
Xiyuan Zhang
Scientist @ AWS AI
Ph.D. @ University of California, San Diego
xiyuanz [AT] amazon.com
Filling Conversation Ellipsis for Better Social Dialog Understanding
Abstract
The phenomenon of ellipsis is prevalent in social conversations. Ellipsis increases the difficulty of a series of downstream language understanding tasks, such as dialog act prediction and semantic role labeling. We propose to resolve ellipsis through automatic sentence completion to improve language understanding. However, automatic ellipsis completion can result in output which does not accurately reflect user intent. To address this issue, we propose a method which considers both the original utterance that has ellipsis and the automatically completed utterance in dialog act and semantic role labeling tasks. Specifically, we first complete user utterances to resolve ellipsis using an end-to-end pointer network model. We then train a prediction model using both utterances containing ellipsis and our automatically completed utterances. Finally, we combine the prediction results from these two utterances using a selection model that is guided by expert knowledge. Our approach improves dialog act prediction and semantic role labeling by 1.3% and 2.5% in F1 score respectively in social conversations. We also present an open-domain human-machine conversation dataset with manually completed user utterances and annotated semantic role labeling after manual completion.
Motivation
Ellipsis, in which a speaker omits words that are understood from context, is a frequent phenomenon in human conversation. Although natural to humans, ellipsis poses a challenge for language understanding in spoken dialog systems.
A possible way to resolve semantic ambiguity caused by ellipsis is to train a model that can automatically complete sentences with ellipsis.
However, automatic completion may introduce errors that can lead to other misunderstandings in downstream tasks. To mitigate the impact of such completion errors, we propose a hybrid framework that considers both utterances with ellipsis and their automatically completed counterparts.
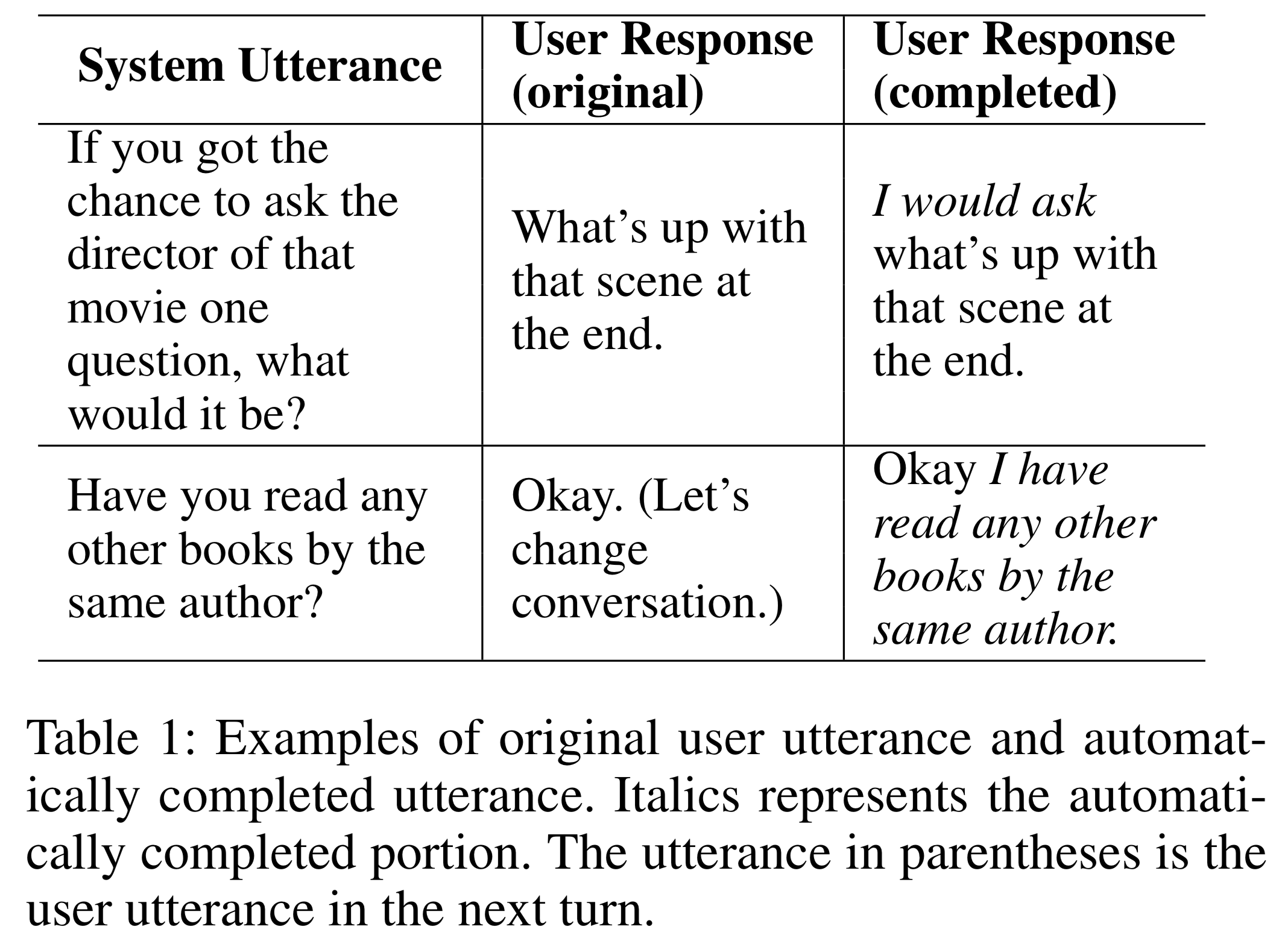
Here are examples of dialog act predication:
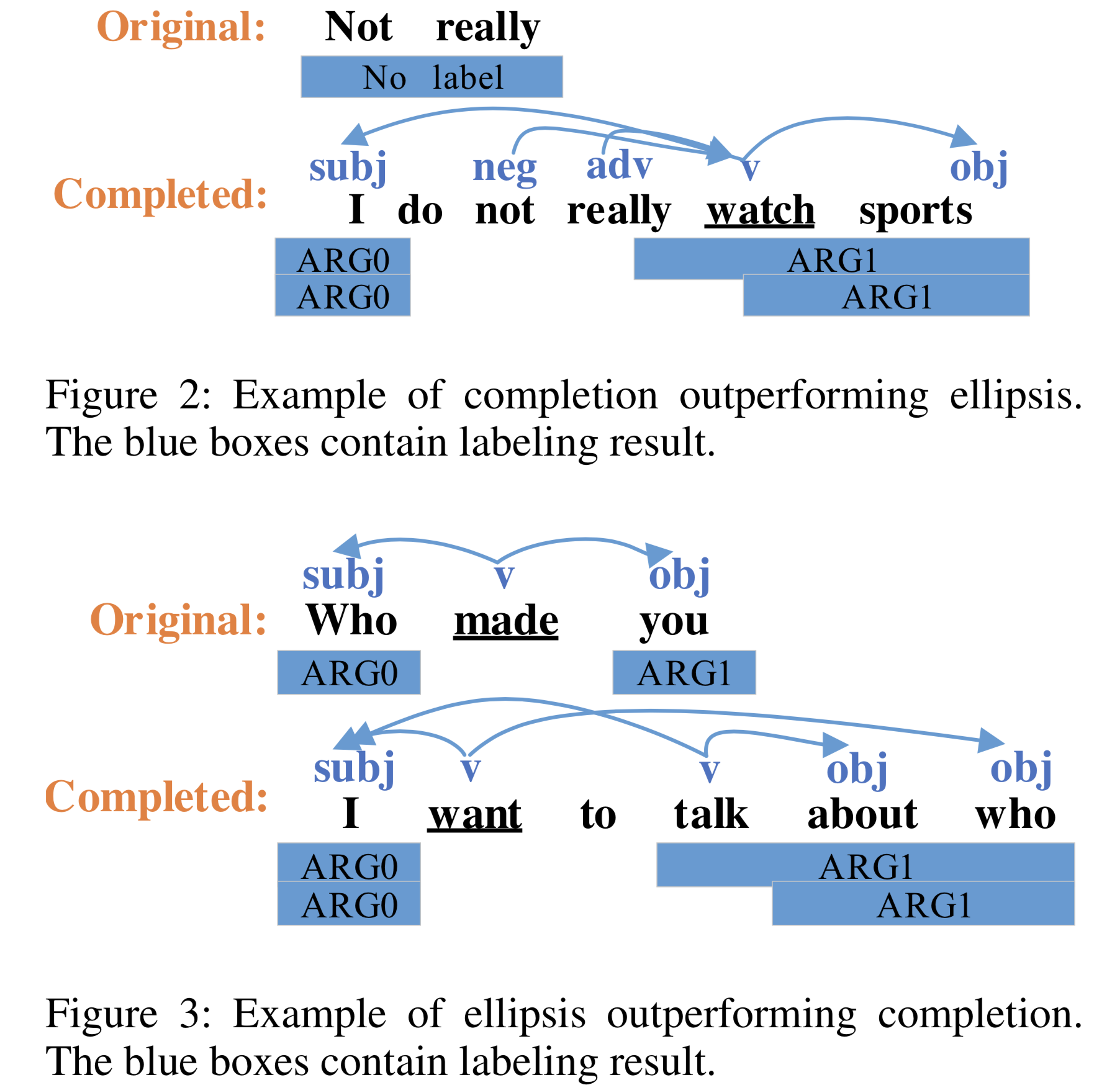
Here are examples of semantic role labeling:
Proposed Model
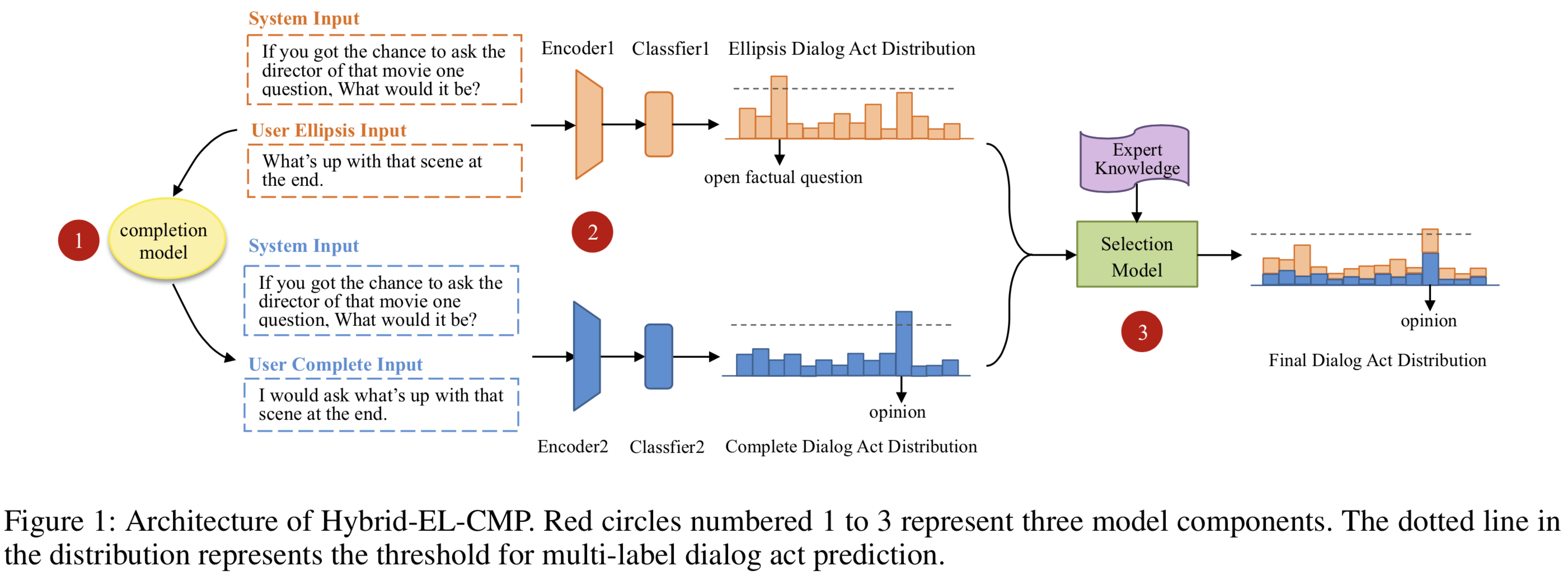
Completion Model
Our completion model is based on Pointer Generator (Vinyals, Fortunato, and Jaitly 2015; Gu et al. 2016; See, Liu, and Manning 2017) which allows copying words directly from the context (previous user utterances in our case) while retaining the ability to generate words from the decoder. These copied words are likely to be the omitted information that we want to complete. Here we use \(\lambda\) to represent a switch probability between generation mode and copy mode, which is calculated from the encoder context vector $h_t$, the decoder input $x_t$ and the decoder hidden states $s_t$ at time step $t$: \(\begin{eqnarray} \lambda = sigmoid(W_\lambda[h^*,x_t,s_t]+b_\lambda) \end{eqnarray}\) We use $P(\omega)$ to represent the distribution over the whole vocabulary to get the word $\omega$ from the decoder. \(\begin{eqnarray*} &P_{gen}(\omega)& = g(h^*,s_t) \tag{1}\\ &P_{copy}(\omega)& = \sum_ia_i^t \tag{2}\\ &P(\omega)& = softmax([\lambda P_{gen}(\omega),(1-\lambda)P_{copy}(\omega)]) \tag{3}\\ \end{eqnarray*}\) Language Understanding Model
We have two encoder-classifier models: the model above is for encoding utterances with ellipsis and the model below is for encoding utterances after completion.
- For dialog act prediction, we leverage the BERT model trained on Wikipedia (Devlin et al.2018)
- For semantic role labeling, we leverage stacked Bi-LSTMs with highway connections trained on CONLL2012 (Pradhan et al. 2012), similar to (He et al. 2017).
Selection Model
We experiment with several selection methods to combine the information of utterances with ellipsis and utterances after completion.
- Logits-based methods:
- Hidden-states-based methods:
- Expert knowledge
Dialog act prediction Model:
We define specific dialog acts that are not suitable to be predicted from complete utterances (e.g. hold)
SRL Model:
Rule-based Method: Choose predictions from the original utterance if the original utterance has a predicate
Probability-based-based Method: For a specific argument, choose predictions from the auto-completed utterance with some probability even if the original utterance has a predicate. This probability is related to the beam search posterior probability for this argument in the completion model.
Annotation Scheme and Datasets
Our dataset is collected in our in-lab user studies with a social bot on the Alexa platform (Gunrock dataset) (Chen et al. 2018a). It consists of real human-machine social conversations that cover a broad range of topics including sports, politics, entertainment, technology, etc.
Utterance Completion Scheme
The original utterances are completed following these rules:
- If the original utterance has ellipsis, then we manually complete the utterance
- If the original utterance is complete and may be readily modified to create an example of ellipsis , then we modify the utterance to create a version containing ellipsis
- If the utterance is complete and not appropriate for creating an ellipsis version, we just keep the original utterance.
Dialog Act Annotation Scheme
The annotation of dialog act dataset follows the scheme of MIDAS (Yu and Yu 2019). We have totally annotated 11,602 user utterances with 23 dialog acts
Semantic Role Labeling Scheme
The format of dataset follows the scheme of CONLLU2012 and the semantic role labeling annotation follows the “English PropBank Annotation Guidelines”. We have totally annotated 1,689 user utterances.
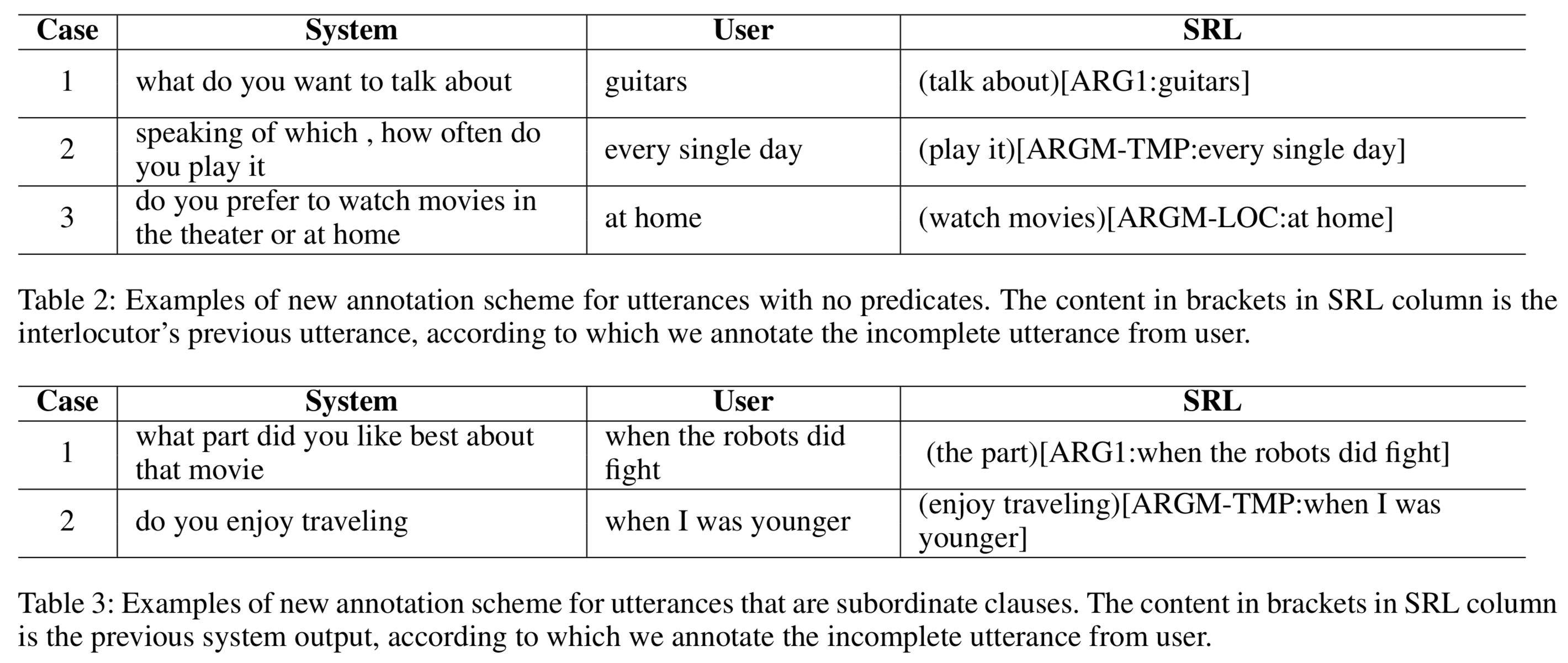
Experimental Results
Our approach improves dialog act prediction and semantic role labeling by 1.3% and 2.5% in F1 score respectively in social conversations. For further analysis of dialog act prediction and SRL:
| Notations | Meaning |
|---|---|
| EL | a single model trained on utterances with ellipsis |
| CMP | a single model trained on utterances after completion |
| Hybrid-EL-EL | two models both trained on utterances with ellipsis |
| Hybrid-CMP-CMP | two models both trained on utterances after completion |
| Hybrid-EL-CMP | the proposed model, one trained on utterances with ellipsis and the other trained on utterances after completion |
| Hybrid-EL-CMP1 | the proposed model with rule-based prediction output |
| Hybrid-EL-CMP2 | the proposed model with probability-based prediction output |
Dialog act prediction
Table 5 shows that Hybrid-EL-CMP performs the best in dialog act prediction
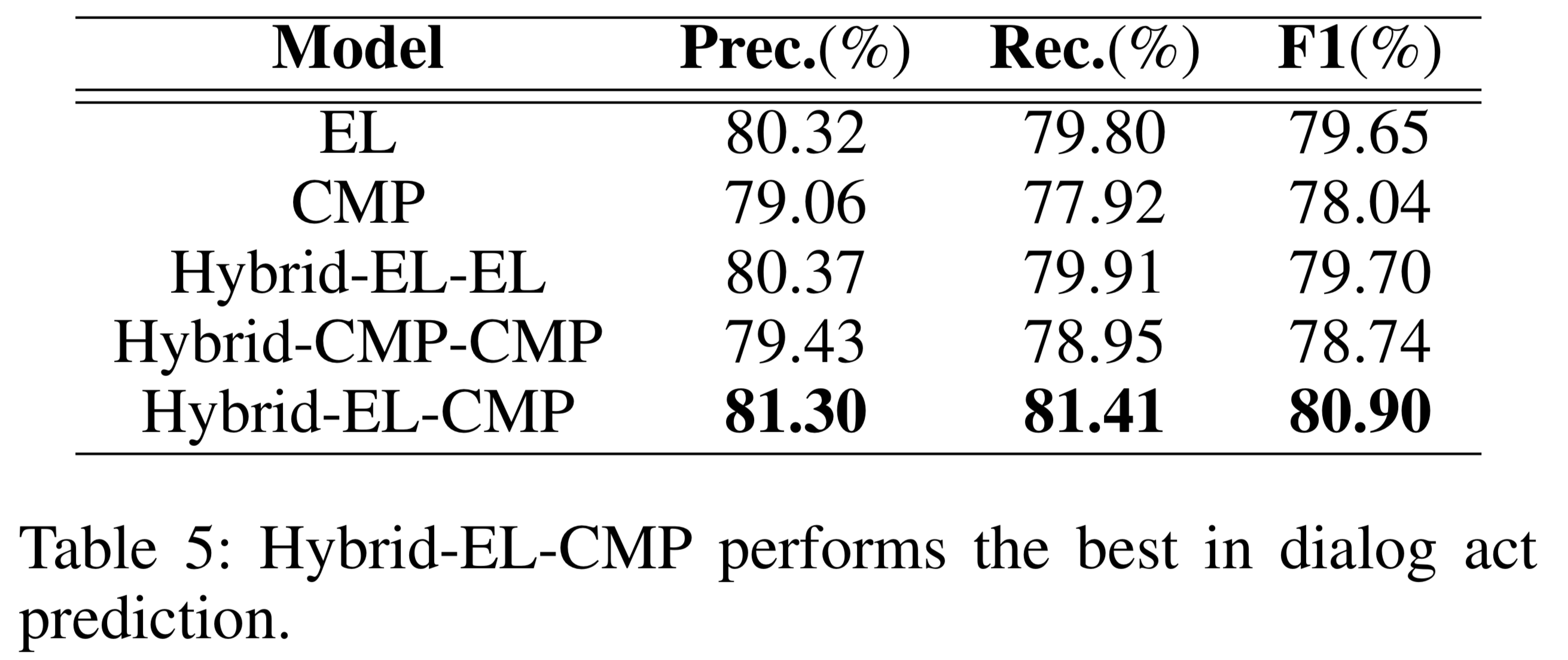
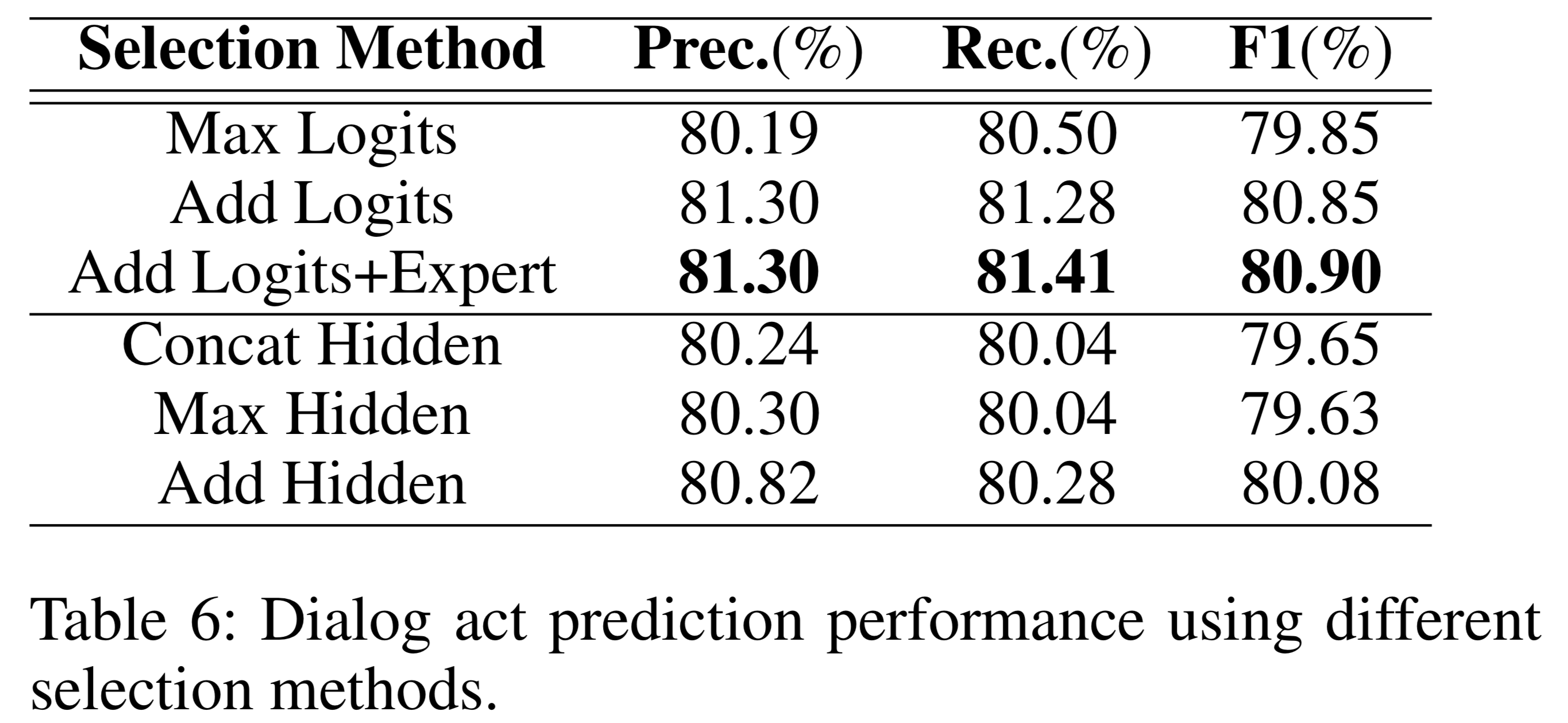
Table 6 shows the dialog act prediction performance using different selection methods.
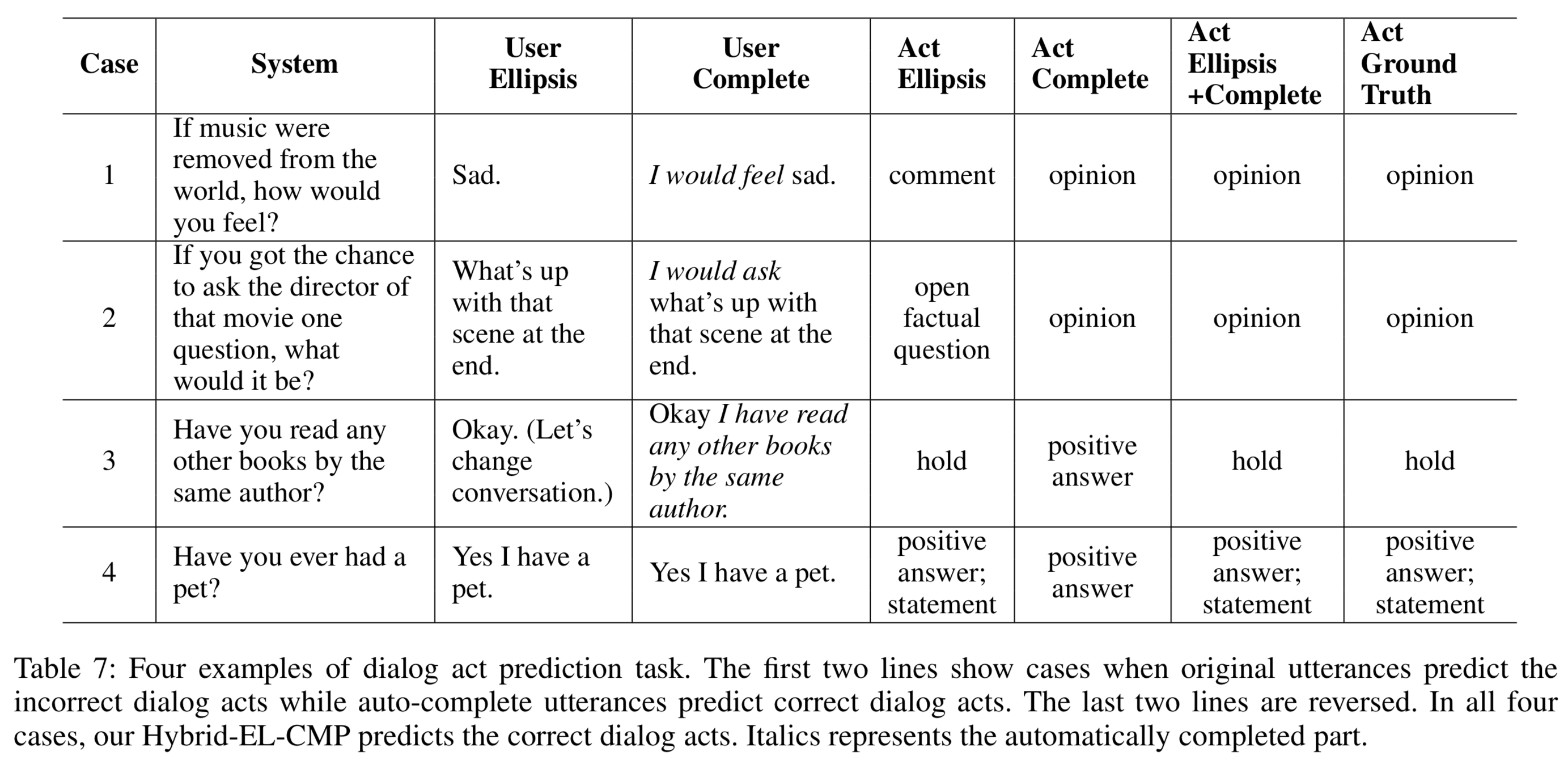
We show here some case studies of dialog act prediction task. The first two lines show cases when original utterances predict the incorrect dialog acts while auto-complete utterances predict correct dialog acts. The last two lines are reversed. In all four cases, our Hybrid-EL-CMP predicts the correct dialog acts. Italics represents the automatically completed part.
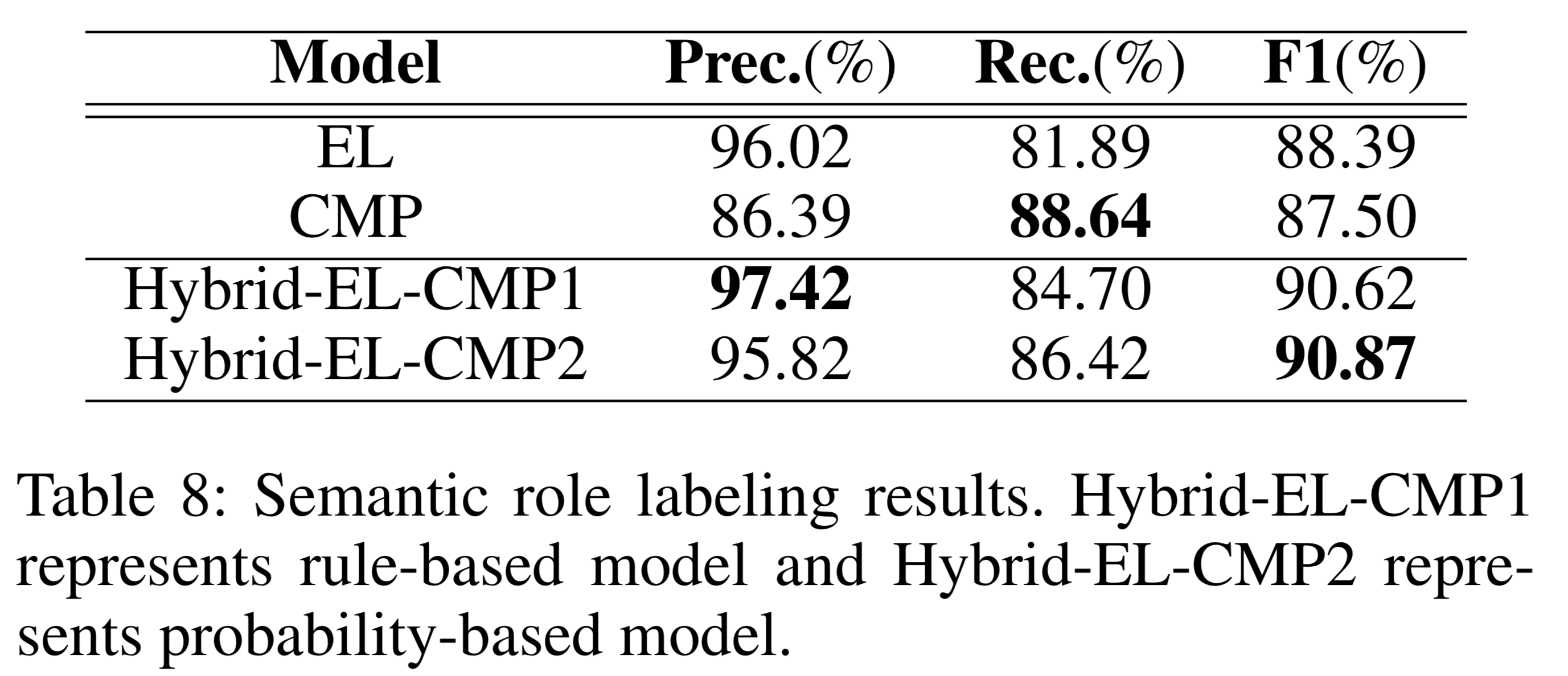
Semantic role labeling
Table 8 shows that Hybrid-EL-CMP2 gets the highest F1 score. But there are cases when Hybrid-EL-CMP1 beats Hybrid-EL-CMP2, and vice versa.
Conclusion
Ellipsis frequently occurs in social conversations. We propose Hybrid-ELlipsis-CoMPlete (Hybrid-EL-CMP) to utilize both original utterances with ellipsis and their automatically completed counterparts for improving language understanding in human-machine social conversations. We show the effectiveness of the proposed approach on language understanding tasks by evaluating on dialog act prediction and semantic role labeling. We believe that the framework can be generalized to other dialog understanding tasks as well, such as syntactic and semantic parsing. We will evaluate these tasks and also our proposed model on other domains such as human-human conversations in the future.